바로 예시로 시작하겠습니다.
A와 B가 약 1km 거리에 있는 사람의 성별을 맞추는 내기를 한다고 가정하겠습니다.
눈이 좋은 A는 99%의 확신을 가지고 남자라고 했습니다.
눈이 좋지 않은 B는 50%의 확률로 남자라고 말했습니다.
그럼 결과는 무승부인가요?
A는 99%의 확률을 가지고 맞췄기 때문에 본인이 이겼다고 주장합니다.
이런 논리로 나온게 logloss 입니다.
다른 예시를 들어보겠습니다.
분류 예측 모델 경진대회에서 남성과 여성을 분류하는 문제가 있을 때,
대회 주최자는 '운이 좋아서 맞춘 사람'과 '실력이 좋아서 맞춘 사람'을 구분하고 싶을 겁니다.
그렇기 때문에 예측한 결과값과 더불어서 모델이 그 값에 얼마나 확신하는지도 확인할 것입니다.
이 사람이 0.2의 확률로 1을 예측했는지 0.9의 확률로 1을 예측했는지 파악하는 것입니다.
그것을 수치화 하기 위해 로그함수를 대입했는데,
아래 그림을 참고해서 더 자세히 설명해보겠습니다.
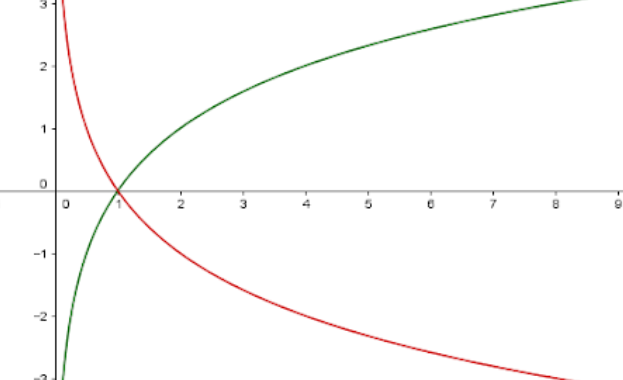
logloss에서 사용하는 그래프는 빨간색 그래프인 -log(x) 형태입니다.
어떤 모델이 분류한 예측값의 확률이 100%라면 -log(1) 인 값을 logloss값으로 반환합니다.
만약 확률이 20%라면 -log(0.2) 인 값을 logloss 값으로 반환하는데,
확률이 낮을수록 logloss 값이 기하급수적으로 증가하게 됩니다.
결국 “ logloss 값은 분류모델에서 평가지표로 사용하는 지표 중 하나이며, 0에 가까울수록 정확하다는 뜻이고, 확률이 낮아질수록 logloss값은 급격하게 커진다 “ 정도로 정리할 수 있겠네요 :)
'Study doc. > Python' 카테고리의 다른 글
| [Python] 알고 써라!! 판다스(Pandas) (1) | 2020.07.23 |
|---|---|
| [Python] 알고 써라!! 넘파이(Numpy) (0) | 2020.07.21 |
| [Python] iloc vs loc (0) | 2020.06.01 |
| [Python] concat vs merge (0) | 2020.06.01 |
| [Python] apply, lambda 함수의 활용 + map 함수 (0) | 2020.06.01 |



