Linear Regression 은 데이터를 가장 잘 표현하는 직선을 찾는 것이라고 했습니다.
그럼 Logistic Regresion 은 뭘까요?
데이터를 가장 잘 분류하는 직선을 찾는 것이라고 할 수 있습니다.
어떻게 그 직선을 찾을까요?
선형회귀와 같은 방법으로 cost function (손실함수, 실제 값과 예측 값과의 차이)을 정의하고, 이를 최소화하는 지점을 gradient descent 기법을 통해 찾으면 됩니다.
잠깐 복습해봅시다.
선형 회귀 (Linear Regression)
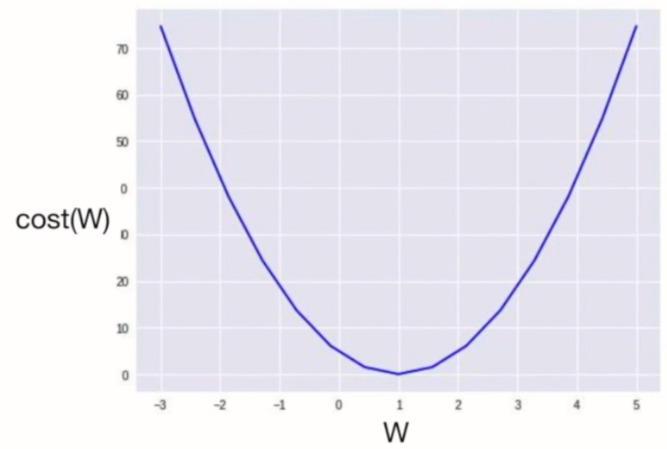
- 가설 함수(H(x)) = w*x + b
- 손실 함수(cost function)

- w 값에 따른 cost 값 변화
로지스틱 회귀 (Logistic Regression)
로지스틱 회귀는 시그모이드(sigmoid) 함수를 기반으로 작동합니다.
시그모이드 함수는 연속적인 값을 0 또는 1, 둘 중 하나의 값으로 변환시켜주는 역할을 합니다.

기본 선형식에 시그모이드 함수를 취해주기 때문에 가설 함수가 선형 회귀와 달라지게 됩니다.
- 가설 함수(H(x)) = sigmoid(z) = 1 / (1 + e^-z)
- z = w*x + b
그래서 w 값에 따른 cost 값의 변화에도 차이가 생기는데,
가설 함수에 지수 함수(exponential function)이 포함되면서 매끄럽던 그래프에 굴곡이 생깁니다.

이렇게 되면 convex function 임을 보장할 수 없기 때문에 최솟값을 찾을 때 gradient descent algorithm 을 사용할 수 없습니다.
따라서 이 그래프를 매끄럽게 해주는 작업이 별도로 필요한데, 그 작업으로 로그 함수를 사용합니다.
왜 로그 함수냐구요?
굴곡이 생긴 이유가 지수 함수였기 때문에 역치함수인 로그 함수를 취해줌으로써 다시 매끄럽게 되는 원리 입니다.
그렇다고 무작정 전체 식에 로그만 씌운다고 해결되지 굴곡이 사라지는 것은 아닙니다.
로그를 어떻게 사용할지 판단하기 위해 손실 함수를 잠깐 가져오겠습니다.
손실 함수의 손실(cost)는 실제 값과 예측 값의 차이 입니다.
따라서 이 값이 작을수록 예측한 값이 정답과 가까워 진다는 말과 같고,
이런 원리를 이용해 데이터와의 차이가 가장 적은 직선을 만들 수 있었습니다.
자!! 그럼 다시 로그를 어떻게 사용할지로 돌아와서!!
실제 값(y)과 예측 값(H(x))이 가까워질수록 (y=1, H(x)=1/ y=0, H(x)=0) cost 값이 0에 가까워지고,
실제 값과 예측 값이 멀어질수록 (y=1, H(x)=0/ y=0, H(x)=1) cost 값이 무한대에 가까워지는 원리로 로그를 사용하겠다는 방향을 잡았습니다.

이제 모든 cost 값을 더한 손실 함수를 통해 최솟값을 찾아야 하는데, 두 가지 케이스로 나누어져 있기 때문에 하나로 합쳐주는 작업을 해주고, 손실 함수를 정의합니다.
- cost

- 손실 함수

손실함수가 정의되었고, convex function 임도 확인되었기 때문에 gradient descent 기법을 통해 최적해를 구하면 끝입니다.

'Study doc. > Machine Learning' 카테고리의 다른 글
| [ML] LightGBM 이해하고 사용하자 (0) | 2020.08.03 |
|---|---|
| [ML] 결정트리(Decision Tree) 한 번에 정리하기 (0) | 2020.07.31 |
| [ML] Linear Regression (0) | 2020.06.21 |
| [ML] XGBoost 이해하고 사용하자 (2) | 2020.06.05 |
| [ML] 앙상블(Ensemble)이 뭐야? (1) | 2020.06.05 |



