지난 시간까지 딥러닝의 한 분야였던 CNN에 대해서 공부했습니다.
이미지를 처리할때 어떻게 하는지, 어떤 layer를 어떤 구조로 얼마나 쌓을지 등을 공부했었죠!
오늘은 딥러닝의 또 다른 방법인 RNN에 대해서 알아볼게요.
CNN은 Neral Network에서 Convolution을 적용한 개념이었다면,
RNN은 NN에서 Recurrent를 적용한 개념이라고 생각하면 될 것 같습니다.
recurrent 라고 하니 약간 재귀적이니 느낌이 나죠?
그럼 한 번 자세히 알아볼게요!!
순서
- RNN 종류
- RNN 작동 원리
- RNN 을 이용한 예시
- Language Model
- Image Captioning
- Visual Question Answering
- Long Short Term Memory (LSTM)
1. RNN 종류
RNN 은 아래 그림과 같이 다양한 입/출력을 처리합니다.
따라서 가변길이의 데이터, 즉 단어로 이루어진 문장이나 프레임으로 이루어진 비디오를 다룰때 주로 사용됩니다.

대표적인 예시를 살펴보면서 감을 익혀보겠습니다.
- one to many : Image Captioning (image -> sequence of words)
- many to one : Sentiment Classification (sequence of words -> sentiment)
- many to many : Machine Translation (seq of words -> seq of words)
- many to many : Video Classification on frame level
2. RNN 작동 원리
그렇다면 이 RNN은 어떻게 작동하는걸까요?
아래의 오른쪽 그림과 같이 input인 x가 RNN의 core cell에 들어갔다가 나오면 output인 y가 출력됩니다.
이 때 RNN의 내부에는 hidden state가 있고, 새로운 입력을 불러들일때마다 매번 업데이트 됩니다.
이렇게 hidden state는 계속해서 feedback 되고, 이런 이유에서 recurrent neural network 라는 이름이 붙여지게 됩니다.

hidden state 가 업데이트 되는 과정을 수식으로 보겠습니다.
새로운 hidden layer(h_t)는 이전의 layer(h_t-1)에 x가 들어오고, 이 값을 특정 함수(ex. tanh)의 입력값으로 가집니다.
여기서 y값을 가지고 싶다면 업데이트된 h_t에 FC layer를 추가해주면 됩니다.
좀 더 쉬운 이해를 위해 many to many RNN을 computational graph로 펴봤습니다.

두 입력값(x, h)에 대해 가중치(W)로 행렬곱을 해준 후, 특정 함수에 들어갑니다.
이 값이 새로운 h가 되고 새로운 x를 만나 같은 과정을 반복합니다.
이렇게 h가 업데이트 되는동안 각각 FC layer를 통해 y 값(class score)을 뽑아낼 수 있고, 이를 이용해서 loss 값도 알 수 있습니다.
마지막으로 모든 loss를 더한 값이 최종 loss 로 결정됩니다.
여기서 중요한 점은 동일한 가중치 행렬을 사용한다는 것입니다.
같은 맥락으로 one to many, many to one도 있습니다.


그리고 이 둘을 합친 개념도 있습니다.
바로 sequence to sequence 모델인데요, 가변 입력과 가변 출력을 가지는 machine translation 을 할 때 사용됩니다.

encoder 역할을 하는 many to one 모델과 decoder 역할을 하는 one to many 모델이 합쳐졌습니다.
encoder에서 가변 입력을 하나의 벡터로 변환한 후, 해당 벡터를 가변 출력으로 반환하는 것입니다.
이제 RNN이 작동하는 과정에 대해서 큰 틀은 잡혔습니다.
" input이 들어오면 이전의 hidden layer와 함께 가중치의 행렬곱을 계산하고, 특정 함수식에 넣는구나.
그리고 사용하는 RNN의 구조에 맞게 FC layer를 추가해서 출력값(y)을 구하고, 정의한 loss 함수로 loss 를 정의하네!
이후로는 backpropagation을 진행하며 최적의 W를 찾으려고 노력하겠다! "
자! 이제 실제로 몇가지 RNN 모델을 살펴볼까요?!
3. RNN 을 이용한 예시
3-1. Language Model
가장 먼저 language model 입니다.
만약 hello 라는 단어를 입력할 때, h 다음으로 e가 나오고, e 다음에 l 이 나오는 등 다음 알파벳을 예측합니다.
아래 그림과 함께 설명해볼게요!

일단 입력값의 종류가 h,e,l,o 총 4개로 4D 벡터로 표현할 수 있습니다.
h가 ([1,0,0,0]) 이고 e가 ([0,1,0,0]) 처럼 말이죠.
이렇게 만든 입력값이 hidden layer와 함께 가중치와 곱해지고, FC layer를 거쳐 각 클래스별 점수를 확인할 수 있습니다.
첫번째 output layer를 보면 ([1.0, 2.2, -3.0, 4.1]) 로 되어있고, 4번째 점수가 가장 높습니다.
즉 h 다음으로 o가 예측 되었는데, 이는 잘못 예측된 것이죠.
따라서 loss가 높게 설정되어 backpropagation을 통해 가중치가 수정될 것입니다.
이제 잘 학습된 모델을 가지고 테스트 할 때를 가정해 보겠습니다.
특정 방법(ex. softmax, cross-entropy)을 통해 각 클래스별 loss 값을 얻었을때, 예측 클래스를 선택하는 두가지 방법이 있습니다.
가장 높은 score를 가진 클래스를 선택하는 방법과 확률분포에서 샘플링하는 방법입니다.
확률분포에서 샘플링하는 방법이 모델의 다양성을 높이기 때문에 좋은 방법이라고 하지만,
딥러닝을 공부하면서 드는 생각이 절대적인건 없다 라는 겁니다. 상황에 따라 다르겠죠.
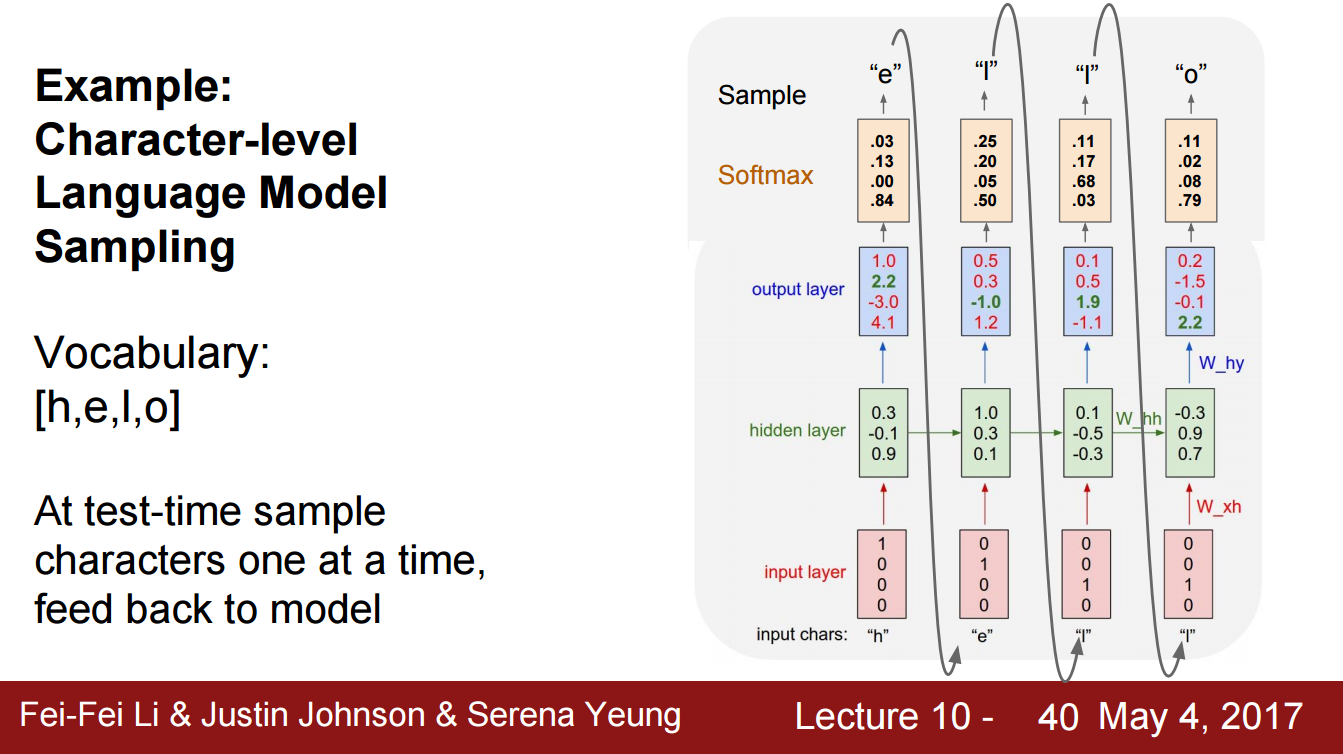
방금 예시는 h, e, l, o 4 가지 종류의 입력값만 있었습니다.
하지만 알파벳의 구성과 단어의 종류는 어마어마하게 많겠죠??
아마 backpropagation을 하려면 시간이 너무 오래걸리거나 gradient vanishing/exploding 문제가 생길 수 있습니다.
아래 왼쪽 그림처럼 말이죠!
따라서 아래 오른쪽 그림처럼 truncated backpropagation 방법으로 진행하게 되는데요,
SGD 방식과 같이 backpropagation을 할때 파트를 나눠서 진행해주는 것입니다.
(forward pass는 쭉 진행됨)


이걸 코드로 구현하여 강의자가 실험해본 결과 흥미로운 사실을 발견했습니다.
우리는 단지 다음 순서의 문자를 예측하기 위한 모델을 만들었는데, 실제로 진행해보니 모델이 데이터의 숨겨진 구조까지 학습하는 것입니다.
소설책을 학습시키니 소설의 구조까지 학습하여 단 나누기, 인용 등의 방식도 구현하는 것입니다.
이는 hidden layer의 벡터 하나하나가 구조를 반영하기 때문일 것이라는 가설이 있는데,
실제 아래 실험 결과를 보시면 문장이 길어질 즈음에 색깔이 빨간색으로 변하며 줄 바꿈 합니다.
(색깔은 hidden vector의 값)
이후에는 다시 파란색으로 돌아오죠.
이런 방식으로 단순히 다음에 올 문자 뿐만 아니라 구조까지 학습하는 것을 알 수 있습니다.

3-2. Image Captioning
강의 초반에 RNN 구조 중 one to many 방식의 예시로 Image Captioning 을 들었습니다.
이미지를 주고, 이 상황에 맞는 문장을 만드는 식입니다.
기본 아이디어는 간단합니다.
image를 CNN을 통해 하나의 벡터로 나타내고(FC layer 삭제), 이를 RNN의 입력값으로 사용합니다.
여기 이미지 정보가 있으니 이 조건에 맞는 문장을 만들어 달라는 말이죠.


하지만 단순한 Image Captioning 에는 문제가 있습니다.
모델이 완전한 지도학습이기 때문에 아래 그림처럼 trian set에 없는 이미지에 대한 test에서는 성능이 좋지 못하다는 것입니다.
따라서 RNN과 Attention Model을 결합하여 조금 더 진보된 방식을 사용합니다.

Attention Model은 말 그대로 특정 부분에 집중(attention)하는 모델입니다.
사람이 이미지에 대한 설명을 할때 특정 물체나 행동을 보는 것처럼
컴퓨터도 같은 원리를 거치도록 하는 노력입니다.
단순 CNN+RNN 모델과는 다르게, attention 모델은 CNN의 output으로 공간정보를 유지한 채 나옵니다.
그리고 RNN을 할 때 모델이 이미지에서 보고 싶은 위치에 대한 분포를 만들어,
train 단계에서 모델이 어느 위치를 주로 봐야하는지 학습합니다.

아래 그림을 보시면 CNN의 output이 L*D 모양으로 나왔습니다.
처음 h_0에서 이미지 위치에 대한 분포(a1)를 만들어냈습니다.
이것을 다시 벡터집합(L*D)과 연산하여 이미지 attention(z1)을 만들고, 다음 스텝의 입력값이 됩니다.
이제 출력값이 두 개가 생기는데,
a2는 이미지에 대한 분포, d1은 vocabulary의 각 단어들의 분포입니다.

이렇게 매 스텝마다 두 종류의 output이 나오고, train이 끝나면 caption을 생성하기 위해 attention을 이동시킵니다.
즉 이미지에서 특정 부분에 집중해서 특정 단어를 예측합니다.
attention의 방법에는 soft attention과 hard attention이 있는데,
간단한 개념을 보면 hard attention 의 경우에는 매 스텝마다 딱 한곳에만 집중하는 반면,
soft attention 의 경우에는 좀 더 유연한 방식을 선택합니다.
(자세한 내용은 강화학습 강의에서 다룬다고 합니다. 간단한 개념만 알고 넘어가죠)

아래 그림을 보시면 실제로 모델이 captioning을 할때 사진의 의미있는 부분에 attention하는 것을 확인할 수 있습니다.
원판(frisbee)이라는 caption이 나올때 이미지의 원판에 집중한 것처럼요!

3-3. Visual Question Answering (VQA)
RNN+Attention 의 조합은 Visual Question Answering 을 할수도 있습니다.
아래 그림처럼 이미지를 보여주고 질문에 대답을 하는 것입니다.

따라서 input이 두 개(이미지, 질문)가 됩니다.
RNN이 질문을 벡터로 요약하고, CNN이 이미지를 벡터로 요약해서 이 둘을 합쳐(ex. concat) FC layer의 input으로 보냅니다.

지금까지 RNN을 활용한 다양한 예시를 공부했습니다.
자세히 어떤 코드로 구현되는지는 모르지만, 어떤 원리로 작동하는지 전체적인 과정을 이해할 수 있었습니다.
VQA를 예로들어 정리하자면
input으로 두개의 값을 받는데 하나는 이미지를 요약한 벡터이고, 다른 하나는 질문을 요약한 벡터입니다.
질문을 요약하기 위해서는 RNN과 attention을 합친 모델을 사용하는데,
먼저 CNN을 통해 이미지를 벡터로 변환하고 RNN의 input으로 사용합니다.
이 때 특정 부분에 집중(attention)하기 위해 이미지의 공간적 구조를 유지하고,
각 스텝별 input을 두 개(이미지에 대한 분포, 단어에 대한 분포)로 받게 됩니다.
이렇게 나온 벡터(질문을 요약한 벡터)와 이미지를 요약한 벡터를 합쳐 최종적으로 loss를 정의합니다.
지금까지는 단일 hidden layer를 고려했습니다.
하지만 실제로는 성능을 높이기 위해 여러개의 hidden layer, 즉 Mulitlayer RNN(보통 2,3,4층)을 사용하게 되는데요,
깊이가 깊어지고 수식이 많아지게 되면 늘 그렇듯 gradient vanishing/ exploding의 문제가 발생하게 됩니다.
(각 스텝에서 가중치(W)는 같고, backpropagation을 할때에 계속해서 곱해주어야 하기 때문)


보통 gradient exploding 문제의 경우에는 gradient의 스케일을 조절하는 gradient clipping으로 해결이 가능하지만,
gradient vanishing 문제는 RNN의 구조를 변경해야 합니다.
그렇게 변경된 구조가 LSTM 입니다.
4. Long Short Term Memory (LSTM)
gradient vanishing/ exploding 문제를 해결하기 위해 LSTM은 내부에만 존재하는 hidden layer(c_t)를 추가했습니다.
backpropagation을 진행할때 계속해서 곱해지는 W를 해결하기 위해서죠.
작동원리를 살펴보겠습니다.
먼저 input인 x와 hidden layer인 h를 쌓고(concat), 가중치 행렬을 곱해줍니다.
여기까지는 RNN과 똑같죠.
RNN의 경우에는 결과값이 바로 새로운 hidden layer가 되지만,
LSTM의 경우에는 4가지 함수(f, i, g, o)의 input으로 가게 됩니다.

이렇게 통과된 값들이 새로운 hidden layer(c_t)의 구성요소로 사용되게 되며,
특히 사용된 함수들이 결과값을 -1~1 혹은 0~1 값으로 변환해주기 때문에 더이상 행렬곱이 아닌 element-wise 곱으로 layer를 업데이트 할 수 있었습니다.

backpropagation을 자세히 살펴보자면
upstream gradient에 forget gate를 곱하기만 하면 gradient가 업데이트 되는 것입니다.

이로써 두 가지 장점이 생겼습니다.
backpropagation을 할때 행렬곱 연산을 하지 않는 것과 매번 다른 element-wise를 수행할 수 있다는 것입니다.
그리고 이 특성을 통해 gradient vanishing/exploding 문제를 완화할 수 있었습니다.
(이전에는 항상 같은 가중치 행렬을 곱해야 했음)

'Study doc. > Deep Learning' 카테고리의 다른 글
| [cs231n] CNN Architecture (0) | 2020.09.12 |
|---|---|
| [cs231n] Neural Network - part 2 (0) | 2020.09.08 |
| [cs231n] Neural Network - part 1 (0) | 2020.09.06 |
| [cs231n] Convolutional Neural Network (CNN) (0) | 2020.08.16 |
| [cs231n] 이미지 분류 초간단 정리 (0) | 2020.08.07 |



